High Level Concepts
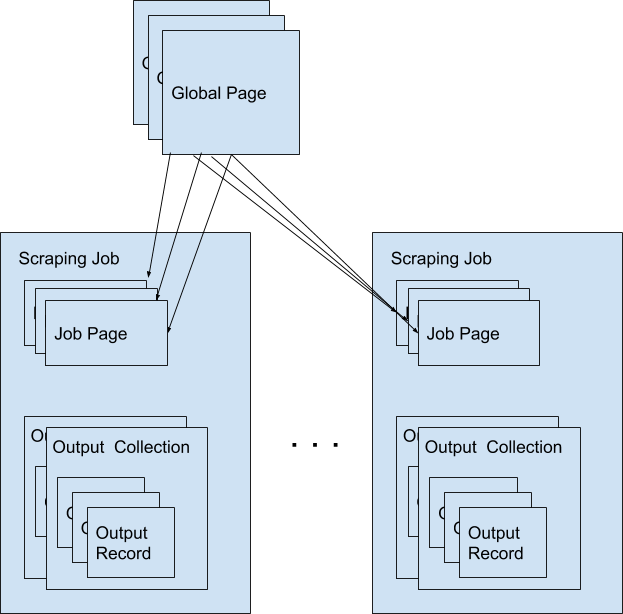
Scrapers
A scraper is a group of tasks that allows users to extract data from the internet. Scrapers consists of a Seeder and Parsers (Currently we only support Ruby language).
Available commands
$ hen scraper help
Commands:
hen scraper create <scraper_name> <git_repository> # Create a scraper
hen scraper delete <scraper_name> # Delete a scraper and related records
hen scraper deploy <scraper_name> # Deploy a scraper
hen scraper deployment SUBCOMMAND ...ARGS # manage scrapers deployments
hen scraper export SUBCOMMAND ...ARGS # manage scraper's exports
hen scraper exporter SUBCOMMAND ...ARGS # manage scraper's exporters
hen scraper finisher SUBCOMMAND ...ARGS # manage scrapers finishers
hen scraper help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper history <scraper_name> # Get historic stats for a job
hen scraper job SUBCOMMAND ...ARGS # manage scrapers jobs
hen scraper list # List scrapers
hen scraper log <scraper_name> # List log entries related to a scraper's current job
hen scraper output SUBCOMMAND ...ARGS # view scraper outputs
hen scraper page SUBCOMMAND ...ARGS # manage pages on a job
hen scraper show <scraper_name> # Show a scraper
hen scraper start <scraper_name> # Creates a scraping job and runs it
hen scraper stats <scraper_name> # Get the current stat for a job
hen scraper update <scraper_name> # Update a scraper
hen scraper task SUBCOMMAND ...ARGS # manage task on a job
hen scraper resource SUBCOMMAND ...ARGS # Get resource settings for a job
hen scraper var SUBCOMMAND ...ARGS # for managing scraper's variables
Global Pages
All web pages that has been fetched by DataHen on behalf of users are stored in a shared cache, called Global Pages. Any web pages that you need to scrape will re-use this global pages if they fit within your freshness-type. If they don’t match your freshness-type, you can specifically force-fetch them from your scraper and job settings.
Available Commands
$ hen globalpage help
Commands:
hen globalpage content <gid> # Show content of a globalpage
hen globalpage help [COMMAND] # Describe subcommands or one specific subcommand
hen globalpage show <gid> # Show a global page
Jobs
When a scraper is run, it creates a scraping job, and will execute the seeder script that you’ve specified. As pages gets fetched, it will get parsed by the parser script that is related to that page.
A job has one of following possible statuses:
Status |
Description |
|---|---|
active |
Job is running |
paused |
User manually paused the job |
cancelled |
User manually cancelled the job, or it is cancelled because another scheduled job on the same scraper has been started. |
done |
Job is done when there are no more to_fetch or to_parse |
Available Commands
$ hen scraper job help
scraper job commands:
hen scraper job cancel <scraper_name> # cancels a scraper's current job
hen scraper job help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper job list <scraper_name> # gets a list of jobs on a scraper
hen scraper job pause <scraper_name> # pauses a scraper's current job
hen scraper job resume <scraper_name> # resumes a scraper's current job
hen scraper job show <scraper_name> # Show a scraper's current job
hen scraper job update <scraper_name> # updates a scraper's current job
Paused Jobs
Sometimes you may find that the status of your job has changed to “paused” on its own. This is a result of your scraper not having any more pages to process because the remaining pages are either in the parsed or failed queue. Specifically, a job will pause if there are no more pages remaining in the following queues:
to_fetch
fetching
to_parse
parsing_started
parsing
To check if there are any pages in the failed queue you can use the following stats command.
hen scraper stats <scraper_name>
You should look at the following failed queue counters and if there are failed pages:
refetch_failed
fetching_failed
fetching_dequeue_failed
parsing_failed
parsing_dequeue_failed
Next step is to fix those failed pages and resume your job. You can use the following commands to list those pages and find the failed ones:
hen scraper page list <scraper_name> --fetch-fail # to list fetch failed pages
hen scraper page list <scraper_name> --parse-fail # to list parse failed pages
hen scraper page list <scraper_name> --status refetch_failed # to list refetch failed pages
Then, once you have updated your scraper to fix any issues, you can refetch or reparse these pages using these commands:
hen scraper page refetch <scraper_name> --gid <gid> # refetch an specific page
hen scraper page refetch <scraper_name> --fetch-fail # refetch all fetch failed pages
hen scraper page refetch <scraper_name> --parse-fail # refetch all parse failed pages
hen scraper page refetch <scraper_name> --status <queue> # refetch all pages by queue
hen scraper page refetch <scraper_name> --page-type <page_type> # refetch all pages by page type
hen scraper page reparse <scraper_name> --gid <gid> # reparse an specific page
hen scraper page reparse <scraper_name> --parse-fail # reparse all parse failed pages
hen scraper page reparse <scraper_name> --status <queue> # reparse all pages by queue
hen scraper page reparse <scraper_name> --page-type <page_type> # reparse all pages by page type
Keep in mind that you can reparse a page as many times you need, but you can only refetch a page no more than 3 times before it goes into refetch_failed status. This is quite useful to avoid infinite loops.
You can also combine the filters on reparse, refetch and limbo commands for a precise search, for example, if you need to reparse all pages with a page_type = product that has been already parsed from a scraper called ebay, then you can combine the filters like this:
hen scraper page reparse ebay --page-type product --status parsed
After resetting at least one page, you can resume the job:
hen scraper job resume <scraper_name>
Job Workers
Job workers are units of capacity that a job can run. A job needs at least one worker for it to run.
There are three kinds of workers:
Parser Worker. This allows you to parse the fetched pages.
Fetcher Worker. This allows you to fetch using regular HTTP method.
Browser Worker. This will fetch using a real browser, and will render and execute any javascripts that are available on the page.
Typically one worker can has the capacity to perform:
Fetching and parsing of up to 100,000 fresh pages per month from the internet. *
Fetching and parsing of up to 300,000 pages per month from the shared cache(global page contents). *
This totals to about 400,000 parsed pages per month. *
* performance varies based on many factors, including: target server capacity, bandwidth, size of pages, scraper profile, etc.
Note: If you need your scraping results sooner, you can purchase more capacity by adding more workers to your account and assigning more workers to your scraper. When you have multiple unused workers on your account, you can choose to either run multiple scrape jobs at once, or you can assign multiple workers to a single scrape job
Job Pages
Any Pages that are added by your scraper so that DataHen can fetch them, are all contained within the job, these are called job pages.
ForceFetch, when set to true, will force a page to be re-fetched if it is not fresh, as determined by freshness-type(day, week, month, year, any) that you have set on the scraper. Note: ForceFetch only works on pages that already exist in the DataHen platform. It has no effect on pages that does not exist, therefore, it will fetch the pages regardless if you force them to or not.
Vars. A job page can have user-defined variables, that you can set when a page is enqueued. This vars can then be used by the parser to do as you wish
Treat a page like a curl HTTP request, where you are in control of lower level things, such as, request method, body, headers, etc.
The following JSON describes the available options that you can use when enqueueing any page to DataHen via a script:
Available Commands
$ hen scraper page help
scraper page commands:
hen scraper page add <scraper_name> <page_json> # Enqueues a page to a scraper's current job
hen scraper page content <scraper_name> <gid> # Show a page's content in scraper's current job
hen scraper page failedcontent <scraper_name> <gid> # Show a page's failed content in scraper's current job
hen scraper page getgid <scraper_name> <page_json> # Get the generated GID for a scraper's current job
hen scraper page help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper page limbo <scraper_name> # Move pages on a scraper's current job to limbo
hen scraper page list <scraper_name> # List Pages on a scraper's current job
hen scraper page log <scraper_name> <gid> # List log entries related to a job page
hen scraper page refetch <scraper_name> # Refetch Pages on a scraper's current job
hen scraper page reparse <scraper_name> # Reparse Pages on a scraper's current job
hen scraper page show <scraper_name> <gid> # Show a page in scraper's current job
hen scraper page update <scraper_name> <gid> # Update a page in a scraper's current job
Search pages
You can search specific pages by executing this command hen scraper page list <scraper_name> you can be more specific and specify some kind of filters to narrow your search, remember that these filters must be a perfect match to your page so you can get the correct results, here is the list of options you can send and its use:
$ hen scraper page list my_scraper -j 123 --page_type test --url http://test.com
scraper page list options:
option :job, :aliases => :j, type: :numeric, desc: 'Set a specific job ID'
option :page_type, :aliases => :t, type: :string, desc: 'Filter by page_type'
option :url, :aliases => :u, type: :string, desc: 'Filter by url'
option :effective_url, :aliases => :U, type: :string, desc: 'Filter by effective_url'
option :body, :aliases => :b, type: :string, desc: 'Filter by body'
option :parent_gid, :aliases => :G, type: :string, desc: 'Filter by parent_gid'
option :page, :aliases => :p, type: :numeric, desc: 'Get the next set of records by page.'
option :per_page, :aliases => :P, type: :numeric, desc: 'Number of records per page. Max 500 per page.'
option :fetch_fail, type: :boolean, desc: 'Returns only pages that fails fetching.'
option :parse_fail, type: :boolean, desc: 'Returns only pages that fails parsing.'
option :status, type: :string, desc: 'Returns only pages with specific status.'
Job Outputs
Outputs are generated by parser scripts. Outputs are contained within a collection that you can specify. By default, if you don’t specify a collection, the output will be stored in the “default” collection. Job outputs are in JSON format.
Important: If you intend to integrate your application with DataHen via the API where you need to download the output data at high scale, it is more performant to download the Job Exports instead.
Available Commands
$ hen scraper output help
scraper output commands:
hen scraper output collections <scraper_name> # list job output collections that are inside a current job of a scraper.
hen scraper output help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper output list <scraper_name> # List output records in a collection that is in the current job
hen scraper output show <scraper_name> <record_id> # Show one output record in a collection that is in the current job of a scraper
Job Exports
Exports are generated by Exporter scripts. This is the most efficient way to download a large amount of data from DataHen.
Available Commands
$ hen scraper export help
scraper export commands:
hen scraper export download <export_id> # Download the exported file
hen scraper export help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper export list # Gets a list of exports
hen scraper export show <export_id> # Show a scraper's export
Job Stats
Knowing your job stats is important and being able to analyze your job stats over the time even more. Datahen understands this and keeps historic stats data on all your jobs for further analyze.
Available Commands
To check your job current stats you can use the following stats command.
hen scraper stats <scraper_name>
To check your job historic stats you can use the following history command.
$ hen scraper help history
Usage:
hen scraper history <scraper_name>
Options:
j, [--job=N] # Set a specific job ID
[--min-timestamp=MIN-TIMESTAMP] # Starting timestamp point in time to query historic stats (inclusive)
[--max-timestamp=MAX-TIMESTAMP] # Ending timestamp point in time to query historic stats (inclusive)
[--limit=N] # Limit stats retrieved
[--order=N] # Order stats by timestamp [DESC]
Description:
Get historic stats for a scraper's current job
Job Error Logs
When an error occurs inside a job, it gets logged. And you can check to see the errors that occur on a job, or even on a particular page
Available Commands
$ hen scraper help log
Usage:
hen scraper log <scraper_name>
Options:
j, [--job=N] # Set a specific job ID
H, [--head=HEAD] # Show the oldest log entries. If not set, newest entries is shown
p, [--parsing=PARSING] # Show only log entries related to parsing errors
s, [--seeding=SEEDING] # Show only log entries related to seeding errors
m, [--more=MORE] # Show next set of log entries. Enter the `More token`
- Description:
Shows log related to a scraper’s current job. Defaults to showing the most recent entries
$ hen scraper page help log
Usage:
hen scraper page log <scraper_name> <gid>
Options:
j, [--job=N] # Set a specific job ID
H, [--head=HEAD] # Show the oldest log entries. If not set, newest entries is shown
p, [--parsing], [--no-parsing] # Show only log entries related to parsing
m, [--more=MORE] # Show next set of log entries. Enter the `More token`
P, [--per-page=N] # Number of records per page. Max 5000 per page.
- Description:
Shows log related to a page in the job. Defaults to showing the most recent entries
Parsers
Parsers are scripts that you create within a scraper in order to extract data from a web page, or to enqueue other pages. The parser scripts are executed as soon as a page is downloaded. You can create a script for a particular type of page, for example, if you were to scrape an e-commerce website, you can have an “index” page type, and a “detail” page type. When you enqueue a page to DataHen, you need to specify the page_type so that the matching parsers for that page_type will be executed.
Reserved words or methods in parser scripts:
page # => Hash. returns the page metadata
page['vars'] # => Hash. returns the page's user-defined variables
content # => String. returns the actual response body of the page
pages # => []. the pages to be enqueued, which will be fetched later
outputs # => []. the array of job output to be saved
save_pages(pages) # Save an array of pages right away and remove all elements from the array. By default this is not necessary because the parser will save the "pages" variable. However, if we are saving large number of pages (thousands), it is better to use this method, to avoid storing everything in memory
save_outputs(outputs) # Save an array of outputs right away and remove all elements from the array. By default this is not necessary because the parser will save the "outputs" variable. However, if we are saving large number of outputs (thousands), it is better to use this method, to avoid storing everything in memory
Available Commands
$ hen parser help
Commands:
hen parser exec <scraper_name> <parser_file> <GID>...<GID> # Executes a parser script on one or more Job Pages within a scraper's current job
hen parser help [COMMAND] # Describe subcommands or one specific subcommand
hen parser try <scraper_name> <parser_file> <GID> # Tries a parser on a Job Page
Seeder
Seeder script is a script that is executed at the start of any job, that allows you to enqueue URLs that needs to be fetched by DataHen.
To Add a seeder, you simply add the following to your config.yaml file:
seeder:
file: ./seeder/seeder.rb
disabled: false
Reserved words or methods in seeder scripts:
pages # => []. The pages to be enqueued, and will be fetched later
outputs # => []. the array of job output to be saved
save_pages(pages) # Save an array of pages right away and remove all elements from the array. By default this is not necessary because the seeder will save the "pages" variable. However, if we are seeding large number of pages (thousands), it is better to use this method, to avoid storing everything in memory
save_outputs(outputs) # Save an array of outputs right away and remove all elements from the array. By default this is not necessary because the seeder will save the "outputs" variable. However, if we are saving large number of outputs (thousands), it is better to use this method, to avoid storing everything in memory
Available Commands
$ hen seeder help
Commands:
hen seeder exec <scraper_name> <seeder_file> # Executes a seeder script onto a scraper's current job.
hen seeder help [COMMAND] # Describe subcommands or one specific subcommand
hen seeder try <scraper_name> <seeder_file> # Tries a seeder file
Finisher
Finisher script is a script that is executed at the end of any job. This allows you to perform actions after your scraper job is done such as creating summaries and starting exporters.
To Add a finisher, you simply add the following to your config.yaml file:
finisher:
file: ./finisher/finisher.rb
disabled: false
Reserved words or methods in finisher scripts:
job_id # The id of the job that has just finished
outputs # => []. the array of job output to be saved
save_outputs(outputs) # Save an array of outputs right away and remove all elements from the array. By default this is not necessary because the seeder will save the "outputs" variable. However, if we are saving large number of outputs (thousands), it is better to use this method, to avoid storing everything in memory
Available Commands
hen finisher help
Commands:
hen finisher exec <scraper_name> <finisher_file> # Executes a finisher script onto a scraper's current job.
hen finisher help [COMMAND] # Describe subcommands or one specific subcommand
hen finisher try <scraper_name> <finisher_file> # Tries a finisher file
hen scraper finisher help
scraper finisher commands:
hen scraper finisher help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper finisher reset <scraper_name> # Reset finisher on a scraper's current job
Exporters
Exporters are a set of configurations that allows you to export data from DataHen into various formats. We currently have several different exporters: JSON, CSV, and Content. To add an exporter, you simply just add some lines of code under your exporters section of your config.yaml like the following example:
seeder:
...
parsers:
...
# the following lines define exporters...
exporters:
- exporter_name: products_json_short # Example JSON Exporter
exporter_type: json
collection: products
write_mode: line
no_tar: true #removes tar and gives just the ending file without subfolder
limit: 100
offset: 10
- exporter_name: details_content_short # Example Content Exporter
exporter_type: content
export_filename: my_json_SID:<sid>_NAME:<name>_JID:<jid>_DATE:<d:yyyyMMdd hh:mm>
no_subfolder: true
export_extension: gz #desired extension for compressed file
compression_type: zip #this make compression to be a .zip file, this overrides export_extension and ignores no_tar
page_type: details
limit: 100
offset: 10
- You can customize the export filename and this has special placeholders that are replaced with some values here is the list and examples:
<jid> => job id
<sid> => scraper ID
<name> => scraper name
<d:format> => date format like this examples yyyyMMdd hh:mm or yyyyMMdd hh:mm:ss or yyyyMMdd using the convention yyyy = year, MM = month, dd = day, hh = hour, mm = minute, ss = second
You can use export_extension to set up the compression extension name, for example instead of tgz you want gz file. If you set compression_type: zip will create a compressed file with .zip extension, this will not mix with export_extension or no_tar and have the priority over those fields. When no_subfolder is true then the compressed file will be on the root withouth having a subfolder on it like normally do. When no_tar is true then compression is set directly on the file without using tar file on it, doing this will have the same behavior as no_subfolder but only will apply to JSON or CSV exports since this works with file directly and content exporter uses folders. Once you have added the above configuration, you need to deploy the scraper first before you can start creating exports. IMPORTANT: Exporter Names must be unique per scraper, because this is how you’re going to run the exporter with.
Available Exporter Commands
$ hen scraper exporter help
scraper exporter commands:
hen scraper exporter list <scraper_name>
hen scraper exporter show <scraper_name> <exporter_name>
hen scraper exporter start <scraper_name> <exporter_name>
Available Export Commands
$ hen scraper export help
scraper export commands:
hen scraper export download <export_id>
hen scraper export list # Gets a list
hen scraper export show <export_id> # Show an export
Automatically Start Exporters
You can automatically start any exporter as soon as the scrape job is done. To do this, simply add start_on_job_done: true to your exporter configuration. The following is an example config file that has the exporters ready to auto-start.
seeder:
...
parsers:
...
# the following lines define exporters...
exporters:
- exporter_name: products_json_short # Example JSON Exporter
exporter_type: json
collection: products
write_mode: line
no_tar: true #removes tar and gives just the ending file without subfolder
limit: 100
offset: 10
start_on_job_done: true # This field will auto start this exporter
- exporter_name: details_content_short # Example Content Exporter
exporter_type: content
page_type: details
export_filename: my_json_SID:<sid>_NAME:<name>_JID:<jid>_DATE:<d:yyyyMMdd hh:mm> #customize file name
no_subfolder: true #put on root without using subfolder
export_extension: gz #desired extension for compressed file
compression_type: zip #this make compression to be a .zip file, this overrides export_extension and ignores no_tar
limit: 100
offset: 10
start_on_job_done: true # This field will auto start this exporter
JSON Exporter
Json exporter allows you to export a collection into json formatted file. Typically, a JSON Exporter looks like this:
exporter_name: <your_exporter_name_here> # Must be unique
exporter_type: json
export_filename: my_json_SID:<sid>_NAME:<name>_JID:<jid>_DATE:<d:yyyyMMdd hh:mm> #customize file name
no_subfolder: true #put on root without using subfolder
export_extension: gz #desired extension for compressed file
compression_type: zip #this make compression to be a .zip file, this overrides export_extension and ignores no_tar
no_tar: true #removes tar and gives just the ending file without subfolder
collection: <collection_here>
write_mode: line # can be `line`,`pretty`, `pretty_array`, or `array`
limit: 100 # limits to how many records to export
offset: 10
start_on_job_done: true
excluded_fields: # list of fields to exclude from JSON records
- foo
- bar
JSON Write Modes
The JSON exporter supports four different write modes, based on your needs: line, pretty, pretty_array, and array.
Write mode of line will export a file with the following content:
{"foo1": "bar1"}
{"foo1": "bar1"}
{"foo1": "bar1"}
Write mode of pretty will export a file with the following content:
{
"foo1": "bar1"
}
{
"foo1": "bar1"
}
{
"foo1": "bar1"
}
Write mode of pretty_array will export the following content:
[{
"foo1": "bar1"
},
{
"foo1": "bar1"
},
{
"foo1": "bar1"
}]
Write mode of array will export the following content:
[{"foo1": "bar1"},
{"foo1": "bar1"},
{"foo1": "bar1"}]
CSV Exporter
CSV exporter allows you to export a collection into a CSV formatted file. Typically, a CSV Exporter looks like this:
exporter_name: <your_exporter_name_here> # Must be unique
exporter_type: csv
export_filename: my_json_SID:<sid>_NAME:<name>_JID:<jid>_DATE:<d:yyyyMMdd hh:mm> #customize file name
no_subfolder: true #put on root without using subfolder
export_extension: gz #desired extension for compressed file
compression_type: zip #this make compression to be a .zip file, this overrides export_extension and ignores no_tar
no_tar: true #removes tar and gives just the ending file without subfolder
collection: <collection_here>
no_headers: false # Specifies if you want the headers row. Default: false
limit: 100 # limits to how many records to export
start_on_job_done: true
fields:
- header: "gid"
path: "_gid"
force_header_quotes: false
force_value_quotes: false
disable_scientific_notation: false
- header: "some_value"
path: "some_value"
force_header_quotes: true
force_value_quotes: false
disable_scientific_notation: true
- header: "some_nested_value"
path: "path.to.your.value"
force_header_quotes: true
force_value_quotes: true
disable_scientific_notation: false
CSV Fields
Pay careful attention to this fields configuration, as, this is where you need to specify the header and the path, so that the CSV exporter knows how to write the csv rows. A CSV Field, contains two attributes, Header, and Path.
Header allows you to set the value of the csv header.
Path allows the CSV exporter to traverse your output record in order to find the correct value based on the dot “.” deliminator. Take a look at the following output record:
{
"foo1": "bar1",
"foo2": { "sub2" : "subvalue2" }
}
In the above example, the path “foo1” produces the value: “bar1” And the path “foo2.sub2” produces the value “subvalue2”
With this combination of Header and Path, the CSV exporter should cover a lot of your use cases when it comes to exporting CSVs. However, if you feel that you have a rare scenario where you’re not able to traverse the output very well by using Path, you should code your parser scripts to output a simpler schema.
Scientific Notation
The CSV standard allows and recommends the use of scientific notation to represent big numbers in order to reduce the CSV file size. This feature is enabled by default, but it can be easily disabled by field by using the “disable_scientific_notation” option, for example:
fields:
- header: my_big_number
path: my_big_number
disable_scientific_notation: true
This way a number like “123000000000000” will be display as is instead of displaying as it’s scientific notation representation “1.23e+14”.
Forcing Double Quotes Enclosure
Double quotes are used on CSV files whenever a value contain the separator character or a new line inside it, while those values without any of these will be written as is. Ignoring double quotes when not required is quite useful to reduce the CSV file size, however, there are some special scenarios on which you might want to force the double quotes enclosures on the header or values of specific fields.
To do this, you can make use if the field options “force_header_quotes” and “force_value_quotes” to force the double quotes into the header and values respectively even when are not needed:
Content Exporter
Content exporter allows you to export the actual content of the page that has been fetched for you. You can export any contents including html, pdf, images, etc. The difference between Content exporter and other exporters, is that, it exports from the list of Pages that you have on your scraper job.
When the exported has done exporting, you will get the actual content files, as well as a CSV file that contains a list of all the contents that has been exported. You can use that CSV file, to know what content files has been exported. This is especially useful, if you want to ingest and process these content files in another system. You can add the export delimiter to export csv using ‘;’ for example using it as the example below, this must be only one character because if not deploy can fail due to yaml not been correct, also to use pipe should be inside commas like this: “|”
Typically, a Content Exporter looks like this:
exporter_name: <your_exporter_name_here> # Must be unique
exporter_type: content
page_type: <page_type>
export_filename: my_json_SID:<sid>_NAME:<name>_JID:<jid>_DATE:<d:yyyyMMdd hh:mm> #customize file name
no_subfolder: true #put on root without using subfolder
export_extension: gz #desired extension for compressed file
compression_type: zip #this make compression to be a .zip file, this overrides export_extension and ignores no_tar
filename_var: <filename_var> # variable to refer to, when naming the file
ignore_extensions: false # filename will have no extension, if true
include_failed_contents: false # self explanatory. Helpful for troubleshooting
limit: 100 # limits to how many records to export
start_on_job_done: true
exporter_delimiter: ; # Exporter delimiter character, should be just one character
Exporting Failed Contents
You can specify to export failed contents as well, this will come handy for troubleshooting purposes. On your exporter’s config, set the following to true:
include_failed_contents: true
When you have specified this to be true, this exporter will save any failed contents in a separate directory.
Note: Keep in mind that failed contents are not saved as a file with their GID as their default filename. They are saved with their CID(Content ID) as the filename. The reason is to remove duplication, as most failed requests to websites display the same exact content repetitiously.
Customizing the File Names
By default, the Content exporter export the content files, with a standard naming convention of:
<gid>.<ext>
If you want to specify a name for the files, you need to set that in the page’s variable, and tell our exporter about what variable it should be. For example, let’s say you have the following Page
{
"gid": "www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e",
"url": "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
}
By default, this will export the page content and save it with the following filename:
www.ebay.com-4aa9b6bd1f2717409c22d58c4870471e.html
Let’s say you want this file to be saved with this filename:
9335.html
You would need to enqueue that page with a variable, like so:
pages << {
url: "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682",
vars: {
my_filename: "9335", # notice we added a "my_filename" var
}
}
And then we would need to set the exporter’s filename_var config like the following:
exporter_name: <your_exporter_name_here>
exporter_type: content
page_type: <page_type>
filename_var: my_filename # Need to tell the exporter how to name the file
And that’s it. This particular content will be then saved as a file with the following filename:
9335.html
Job Task
A task is an action or process that is running in the background. You can monitor them and also search for specific tasks, depending on certain options.
For example, when you execute an export, reparse, refetch or send job pages to limbo a new background task will be created. This task is the one that you can monitor.
Available Commands
$ hen scraper task help
scraper task commands:
hen scraper task help [COMMAND] # Describe subcommands or one specific subcommand
hen scraper task list <scraper_name> # List Pages on a scraper's current job
hen scraper task show <scraper_name> <task_id> # Show a page in scraper's current job
Here are the Commands to be added to improve your results:
Task list Options
Usage:
hen scraper task list <scraper_name>
Options:
j, [--job=N] # Set a specific job ID
p, [--page=N] # Get the next set of records by page.
P, [--per-page=N] # Number of records per page. Max 500 per page.
[--status=one two three] # Returns only tasks with specific status.
[--action=one two three] # Returns only tasks with specific action.
[--include-system], [--no-include-system] # If it is true, will returns all actions. If it is false only tasks with specific action ["refetch", "reparse", "terminate"].
Description:
List all tasks in a scraper's current job or given job ID.
job: To filter the information for an specific job ID.
hen scraper task list <scraper_name> -j 5 # Example for Job ID number 5
hen scraper task list <scraper_name> --job 5 # Example for Job ID number 5
To use the paginator, use the option page:
hen scraper task list <scraper_name> --page 1 # Example for page number 1
hen scraper task list <scraper_name> -p 1 # Example for page number 1
To specify hoy many records per pages you want to be display, use per_page option:
hen scraper task list <scraper_name> --per_page 8 # Example for 8 number of records per page
hen scraper task list <scraper_name> -P 8 # Example for 8 number of records per page
status: This is the list of available statuses to use to filter.
to_process
processing
failed
done
You can mix them or just filter by one, you just need to write the options and leave a blank space between them to separate each other.
hen scraper task list <scraper_name> --status done # Example for status done
hen scraper task list <scraper_name> --status to_process done # Example for status to_process and done
hen scraper task list <scraper_name> --status failed # Example for status failed
action: This is the list of available action options to filter.
refetch
reparse
terminate
You can mix them or just filter by one, you just need to write the options and leave a blank space between them to separate each other.
hen scraper task list <scraper_name> --action reparse # Example for action reparse
hen scraper task list <scraper_name> --action refetch reparse # Example for action refetch and reparse
hen scraper task list <scraper_name> --action refetch reparse terminate # Example for action refetch, reparse and terminate
“include-system”: If you don’t want any restriction for action, and you need to list all of them you can activate this option, just by including it in the query.
hen scraper task list <scraper_name> --include_system # Example for all the actions, and not for only refetch, reparse and terminate
And of course, you can mix them all
hen scraper task list <scraper_name> -j 5
hen scraper task list <scraper_name> -j 5 --page 1 --per_page 8
hen scraper task list <scraper_name> -j 5 --action refetch reparse --status done
hen scraper task list <scraper_name> -j 5 --status done --include_system
hen scraper task list <scraper_name> -j 5 --include_system
hen scraper task list <scraper_name> -j 5 --action refetch reparse --page 1 --per_page 8 --status done --include_system
hen scraper task list <scraper_name> --action refetch reparse --status done
hen scraper task list <scraper_name> --status done
hen scraper task list <scraper_name> --include_system
hen scraper task list <scraper_name> --page 1 --per_page 8 --status done to_process --include_system
Task show Options
This will help when you already know the task ID number, so only this information will be displayed.
Usage:
hen scraper task show <scraper_name> <task_id> # Show a task in scraper's current job
Options:
j, [--job=N] # Set a specific job ID
Description:
Shows a task in a scraper's current job or given job ID.
Job
For jobs you can use it like this:
hen scraper task show <scraper_name> <task_id> # Example for current job
hen scraper task show <scraper_name> <task_id> -j 5 # Example for Job ID number 5
Resource Settings
If you need to list a Job’s or Scraper’s custom resource settings, you can use the following command:
Available Commands
hen scraper resource list # List Resources on a scraper's current job
You can use the following filters to improve your results:
List Options
Usage:
hen scraper resource list
Options:
s, [--scraper-name=SCRAPER_NAME] # Filter by a specific scraper_name
j, [--job=N] # Set a specific job ID
[--pod=POD] # Returns only tasks with specific pod.
[--container=CONTAINER] # Returns only tasks with specific container.
[--executor=EXECUTOR] # Returns only tasks with specific executor.
Description:
List of resources in a scraper's current job or given job ID.
The –scraper_name and –job are exclusive, but you can mix them with the other filters.
hen scraper resource list --scraper_name 'ebay'
hen scraper resource list --job 5
hen scraper resource list --scraper_name 'ebay' --container 'fetcher'
Schemas
For output records that needs to follow a certain schema, we support the use of json-schema.org v4, v6, and v7 to validate your collection outputs.
To learn more on how to write your schema files, please visit Understanding JSON Schema.
You can also easily generate a your JSON schema, from a regular JSON record by visiting: jsonschema.net. Doing so will make it much easier to get started with building your schema files.
To see an example of how a scraper uses a schema, visit the following project.
To specify any schema to collection(s), you need to do the following steps:
1. Create the json schema file
Ideally the convention to organize your schema files is to create a directory called ./schemas in the root project directory, and then put all the related files inside.
In this example let’s create a schema file that will validate contact information. In this case, you can create the file ./schemas/contact.json with the following content:
{
"type": "object",
"properties": {
"name": { "type": "string" },
"email": { "type": "string" },
"address": { "type": "string" },
"telephone": { "type": "string" }
},
"required": ["name", "email"]
}
This file contains the actual json-schema that will be used to validate an output record.
2. Create the schema config file and list the schema file that will be used to validate the collection(s)
Once you’ve created the schema file in step 1, you now need to create a schema config file. Let’s create the file ./schemas/config.yaml file with the following content:
schemas:
- file: ./schemas/contacts.json
collections: "contacts,contacts1,contacts2" # you can put multiple collections to be validated by the same schema file
disabled: false
3. Update your config.yaml file to include the schema config file.
Once you’ve created the schema config file, you now need to refer to this schema config file from your project’s main config YAML file. Now, add the following content to your ./config.yaml
schema_config:
file: ./schemas/config.yaml
disabled: false
Once this is done, and you’ve deployed your scraper, any time your script will try to save any output into your specified collections, they will be validated based on the schemas that you’ve specified.